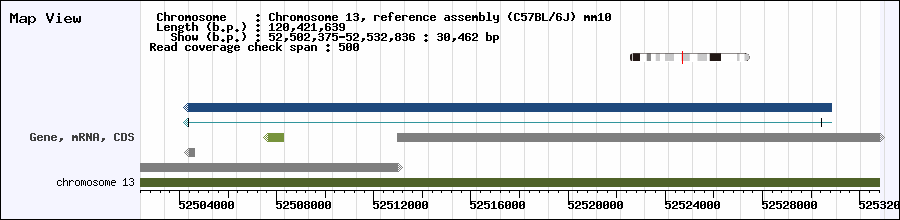
| Reports |
|---|
| substitution |
|---|
| cSNPs | 4 |
|---|
| Insertion | 28 |
|---|
| Deletion | 35 |
|---|
| SNPs |
 +1kb
+1kb
52530997(c.-22728G>A),
52531014(c.-22745A>C),
52531126(c.-22857C>A),
52531129(c.-22860A>C),
52531224(c.-22955C>G),
52531286(c.-23017C>T),
52531452(c.-23183C>G),
52531491(c.-23222C>T),
52531510(c.-23241A>C),
52531929(c.-23660G>T),
52531947(c.-23678C>T),
52532056(c.-23787G>A),
52532300(c.-24031T>A),
52532375(c.-24106A>G),
52532580(c.-24311A>T),
52532704(c.-24435A>C),
52532819(c.-24550A>G),
52532821(c.-24552T>G),
52532980(c.-24711C>T),
52532985(c.-24716T>C),
52533024(c.-24755T>C),
52533140(c.-24871T>C),
52533264(c.-24995A>G),
52533309(c.-25040A>G),
52533449(c.-25180T>C),
52533587(c.-25318G>A),
52533727(c.-25458A>C),
52533821(c.-25552G>A),
52533830(c.-25561A>G),
52533858(c.-25589A>T),
52533859(c.-25590A>C),
52533879(c.-25610C>T),
52533901(c.-25632C>T),
52533914(c.-25645G>A),
52534009(c.-25740C>T),
52534269(c.-26000A>T),
52534313(c.-26044G>A),
52534314(c.-26045T>C),
52534349(c.-26080T>C),
52534392(c.-26123A>G),
52534407(c.-26138T>A),
52534456(c.-26187A>G),
52534463(c.-26194A>G),
52534502(c.-26233C>T),
52534512(c.-26243A>G),
52534533(c.-26264G>T),
52534559(c.-26290G>A),
52534730(c.-26461T>A),
52535127(c.-26858A>T),
52535128(c.-26859G>A),
52535532(c.-27263G>A),
52535598(c.-27329C>G),
52535764(c.-27495A>G),
52535780(c.-27511C>A),
- 5'UTR
- CDS
- 3'UTR
52504937(c.*2733G>C),
52505214(c.*2456A>G),
52506179(c.*1491C>T),
52506212(c.*1458C>T),
52506251(c.*1419C>T),
52506267(c.*1403T>G),
52506292(c.*1378T>C),
52506530(c.*1140T>C),
52506929(c.*741T>A),
52507020(c.*650T>C),
52507120(c.*550T>C),
52507449(c.*221T>C),
52507632(c.*38C>T),
- INTRON
52508345(c.-36-40G>T),
52508394(c.-36-89T>G),
52508433(c.-36-128T>C),
52508676(c.-36-371C>A),
52508738(c.-36-433A>C),
52508755(c.-36-450G>A),
52508768(c.-36-463A>G),
52508838(c.-36-533T>C),
52508958(c.-36-653T>C),
52509119(c.-36-814T>C),
52509297(c.-36-992A>T),
52509307(c.-36-1002G>A),
52509363(c.-36-1058A>G),
52509537(c.-36-1232T>C),
52509727(c.-36-1422T>G),
52510086(c.-36-1781A>G),
52510422(c.-36-2117T>C),
52510511(c.-36-2206T>C),
52510519(c.-36-2214G>A),
52510620(c.-36-2315A>G),
52510659(c.-36-2354C>A),
52510674(c.-36-2369C>T),
52510700(c.-36-2395A>T),
52510767(c.-36-2462T>C),
52510795(c.-36-2490C>T),
52510801(c.-36-2496G>A),
52510998(c.-36-2693G>C),
52511099(c.-36-2794A>T),
52511103(c.-36-2798T>C),
52511131(c.-36-2826A>G),
52511376(c.-36-3071A>G),
52511425(c.-36-3120A>G),
52511434(c.-36-3129G>A),
52511580(c.-36-3275C>T),
52511716(c.-36-3411C>T),
52512016(c.-36-3711A>G),
52512017(c.-36-3712C>T),
52512024(c.-36-3719G>A),
52512084(c.-36-3779C>T),
52512100(c.-36-3795G>A),
52512160(c.-36-3855C>A),
52512174(c.-36-3869C>A),
52512278(c.-36-3973G>T),
52512349(c.-36-4044A>G),
52512519(c.-36-4214G>A),
52512549(c.-36-4244G>T),
52512880(c.-36-4575A>C),
52512910(c.-36-4605A>G),
52513183(c.-36-4878C>T),
52513968(c.-36-5663T>C),
52514053(c.-36-5748A>G),
52514117(c.-36-5812G>C),
52514560(c.-36-6255C>T),
52514678(c.-36-6373G>A),
52515718(c.-36-7413T>A),
52516120(c.-36-7815C>A),
52516393(c.-36-8088C>T),
52516585(c.-36-8280T>C),
52516664(c.-36-8359T>G),
52517094(c.-36-8789A>G),
52517106(c.-36-8801G>A),
52517519(c.-36-9214C>T),
52517980(c.-36-9675G>C),
52518004(c.-36-9699G>A),
52518258(c.-36-9953C>T),
52518414(c.-36-10109G>A),
52518665(c.-36-10360C>T),
52518672(c.-36-10367T>C),
52518722(c.-36-10417C>T),
52518835(c.-36-10530G>A),
52519011(c.-36-10706A>G),
52519209(c.-36-10904C>T),
52519384(c.-37+11036G>T),
52519790(c.-37+10630G>T),
52519825(c.-37+10595G>A),
52519943(c.-37+10477G>A),
52520445(c.-37+9975A>G),
52520501(c.-37+9919G>A),
52521404(c.-37+9016G>A),
52521584(c.-37+8836C>A),
52521749(c.-37+8671T>C),
52521910(c.-37+8510T>C),
52522146(c.-37+8274A>C),
52522213(c.-37+8207A>G),
52522222(c.-37+8198C>T),
52522330(c.-37+8090C>T),
52522378(c.-37+8042C>T),
52522423(c.-37+7997C>T),
52522459(c.-37+7961A>G),
52522497(c.-37+7923T>C),
52522593(c.-37+7827T>C),
52522618(c.-37+7802A>T),
52522622(c.-37+7798C>T),
52522696(c.-37+7724T>C),
52522760(c.-37+7660T>C),
52522792(c.-37+7628T>C),
52522823(c.-37+7597T>C),
52523007(c.-37+7413T>C),
52523026(c.-37+7394T>A),
52523034(c.-37+7386G>C),
52523054(c.-37+7366G>A),
52523059(c.-37+7361G>A),
52523177(c.-37+7243T>G),
52523192(c.-37+7228T>C),
52523244(c.-37+7176G>A),
52523275(c.-37+7145G>A),
52523284(c.-37+7136C>T),
52523330(c.-37+7090A>C),
52523400(c.-37+7020A>G),
52523505(c.-37+6915A>C),
52523534(c.-37+6886T>C),
52523547(c.-37+6873A>T),
52523590(c.-37+6830A>G),
52523976(c.-37+6444T>C),
52524062(c.-37+6358A>C),
52524208(c.-37+6212C>T),
52524370(c.-37+6050T>G),
52524476(c.-37+5944G>C),
52524555(c.-37+5865G>A),
52524602(c.-37+5818A>G),
52524607(c.-37+5813C>T),
52524613(c.-37+5807C>T),
52524662(c.-37+5758C>T),
52524795(c.-37+5625A>G),
52524886(c.-37+5534G>A),
52525063(c.-37+5357C>T),
52525197(c.-37+5223G>A),
52525220(c.-37+5200G>A),
52525255(c.-37+5165G>T),
52525266(c.-37+5154G>T),
52525365(c.-37+5055C>T),
52525382(c.-37+5038A>G),
52525441(c.-37+4979T>G),
52525444(c.-37+4976A>G),
52525587(c.-37+4833G>A),
52525638(c.-37+4782T>C),
52525768(c.-37+4652C>G),
52525786(c.-37+4634C>T),
52525790(c.-37+4630C>T),
52525808(c.-37+4612T>C),
52526242(c.-37+4178C>T),
52526252(c.-37+4168C>T),
52526376(c.-37+4044A>G),
52526386(c.-37+4034C>G),
52526528(c.-37+3892T>C),
52526693(c.-37+3727T>G),
52526719(c.-37+3701T>C),
52526740(c.-37+3680T>C),
52526742(c.-37+3678T>C),
52526819(c.-37+3601C>T),
52527034(c.-37+3386G>C),
52527081(c.-37+3339T>C),
52527249(c.-37+3171T>C),
52527289(c.-37+3131C>T),
52527316(c.-37+3104G>C),
52527401(c.-37+3019T>C),
52527536(c.-37+2884T>A),
52527674(c.-37+2746A>G),
52527720(c.-37+2700C>A),
52527773(c.-37+2647T>C),
52527900(c.-37+2520G>A),
52527917(c.-37+2503G>A),
52527969(c.-37+2451A>T),
52527972(c.-37+2448T>C),
52528007(c.-37+2413T>C),
52528100(c.-37+2320A>G),
52528128(c.-37+2292A>G),
52528385(c.-37+2035T>C),
52528426(c.-37+1994C>T),
52528458(c.-37+1962G>A),
52528468(c.-37+1952A>C),
52528487(c.-37+1933C>G),
52528603(c.-37+1817T>C),
52528623(c.-37+1797A>G),
52528741(c.-37+1679A>G),
52528742(c.-37+1678C>T),
52528804(c.-37+1616G>C),
52528915(c.-37+1505C>T),
52529024(c.-37+1396T>C),
52529183(c.-37+1237G>A),
52529199(c.-37+1221A>T),
52529218(c.-37+1202G>T),
52529273(c.-37+1147T>G),
52529697(c.-37+723A>C),
52529810(c.-37+610T>A),
52530077(c.-37+343C>T),
52530299(c.-37+121T>A),
52530315(c.-37+105G>T),
52530365(c.-37+55G>A),
52530382(c.-37+38A>G),
-
-1kb
52499393(c.*8277A>G),
52499421(c.*8249G>T),
52499450(c.*8220T>G),
52499517(c.*8153A>C),
52499654(c.*8016T>G),
52499680(c.*7990A>G),
52499807(c.*7863A>G),
52499887(c.*7783T>C),
52500227(c.*7443G>A),
52500296(c.*7374C>T),
52500312(c.*7358A>G),
52500397(c.*7273T>C),
52500506(c.*7164A>T),
52500507(c.*7163C>A),
52500509(c.*7161T>C),
52500950(c.*6720C>G),
52501061(c.*6609G>T),
52501247(c.*6423C>A),
52501523(c.*6147C>T),
52501606(c.*6064T>C),
52501629(c.*6041T>C),
52501704(c.*5966C>A),
52501774(c.*5896G>A),
52501782(c.*5888C>T),
52501839(c.*5831C>T),
52502482(c.*5188C>T),
52502999(c.*4671T>C),
52503075(c.*4595T>C),
52503139(c.*4531A>T),
52503194(c.*4476T>C),
52503274(c.*4396T>A),
52503414(c.*4256A>T),
52503671(c.*3999A>G),
52503694(c.*3976C>T),
52503853(c.*3817C>T),
52503973(c.*3697T>C),
52503983(c.*3687T>C),
52504056(c.*3614A>G),
52504091(c.*3579A>G),
52504141(c.*3529C>T),
|
|---|
| Insertions |
-
+1kb
- 5'UTR
- CDS
- 3'UTR
- INTRON
52508569 (c.-36-265_-36-264insTCTC),
52509161 (c.-36-857_-36-856insCCA),
52510399 (c.-36-2095_-36-2094insCC),
52512859 (c.-36-4555_-36-4554insCA),
52513575 (c.-36-5271_-36-5270insT),
52515419 (c.-36-7115_-36-7114insT),
52516002 (c.-36-7698_-36-7697insGG),
52516052 (c.-36-7748_-36-7747insTGTG),
52517007 (c.-36-8704_-36-8703dupAA),
52517785 (c.-36-9481dupT),
52520007 (c.-37+10412_-37+10413insA),
52521790 (c.-37+8627_-37+8629dupCTC),
52522075 (c.-37+8344_-37+8345insCATCC),
52522264 (c.-37+8155_-37+8156insCT),
52525963 (c.-37+4456_-37+4457insACAC),
-
-1kb
|
|---|
| Deletions |
-
+1kb
- 5'UTR
- CDS
- 3'UTR
- INTRON
52510873 (c.-36-2570_-36-2569delTT),
52511232 (c.-36-2932_-36-2928delGTTTC),
52512195 (c.-36-3896_-36-3891delCTCCCC),
52512850 (c.-36-4546delA),
52516071 (c.-36-7773_-36-7767delCTCTTCT),
52518053 (c.-36-9754_-36-9749delTCTTTC),
52520074 (c.-37+10344_-37+10345delTA),
52522020 (c.-37+8391_-37+8399delCACACTATG),
52522124 (c.-37+8292_-37+8295delACAC),
52522240 (c.-37+8172_-37+8179delTCTCCCCC),
52523164 (c.-37+7255delA),
52524807 (c.-37+5612delA),
52526007 (c.-37+4412delC),
52527464 (c.-37+2955delT),
52527476 (c.-37+2943delA),
52527480 (c.-37+2939delA),
52527834 (c.-37+2585delA),
52528289 (c.-37+2130delT),
52529218 (c.-37+1200_-37+1201delCC),
52529989 (c.-37+430delG),
-
-1kb
|
|---|
| coding sequence substitutions |
|---|
| premature termination by the nucleotide substitution | 0 |
|---|
| synonymous num | 4 |
|---|
| non-synonymous num | 0 |
|---|
| synonymous substitutions |
52507768 (p.Leu168Leu),
52507883 (p.Arg129Arg),
52507892 (p.Ser126Ser),
52508135 (p.Arg45Arg),
|
|---|
| non-synonymous substitutions |
|
|---|
B6 transcript
(ENSMUST00000057442)
|
MPEQSNDYRVAVFGAGGVGKSSLVLRFVKGTFRESYIPTVEDTYRQVISCDKSICTLQIT
DTTGSHQFPAMQRLSISKGHAFILVYSITSRQSLEELKPIYEQICEIKGDVESIPIMLVG
NKCDESPNREVQSSEAEALARTWKCAFMETSAKLNHNVKELFQELLNLEKRRTVSLQIDG
KKSKQQKRKEKLKGKCVVM*
|
|
MSMv4 transcript
|
MPEQSNDYRVAVFGAGGVGKSSLVLRFVKGTFRESYIPTVEDTYRQVISCDKSICTLQIT
DTTGSHQFPAMQRLSISKGHAFILVYSITSRQSLEELKPIYEQICEIKGDVESIPIMLVG
NKCDESPNREVQSSEAEALARTWKCAFMETSAKLNHNVKELFQELLNLEKRRTVSLQIDG
KKSKQQKRKEKLKGKCVVM*
|
| homology | 100.00 (200 / 200) |
|---|
|